介绍
这里介绍两种语义结构:
- Constituency Parsing:句法分析,Context-free grammars(CFGs),上下文无关语法,赋予每个单词一个词性类别,单词组合成短语,短语递归形成更大的短语
- Dependency Parsing:直接通过单词与其他单词的关系表示句子的结构,表示单词依赖于(修饰或是其参数)其他单词
Dependency Parsing缺陷
不同的自然语言有不同的组织结构,每种自然语言都有独特的二义问题(ambiguity),即同一个句子通过不同Dependency Parsing分析会得到不同语义树,进而得到不同的语句意思.
总的可能的语义数目极限情况下大概是随着字符串的提示可能是指数级增加,所以有一些方法来解决这些问题.
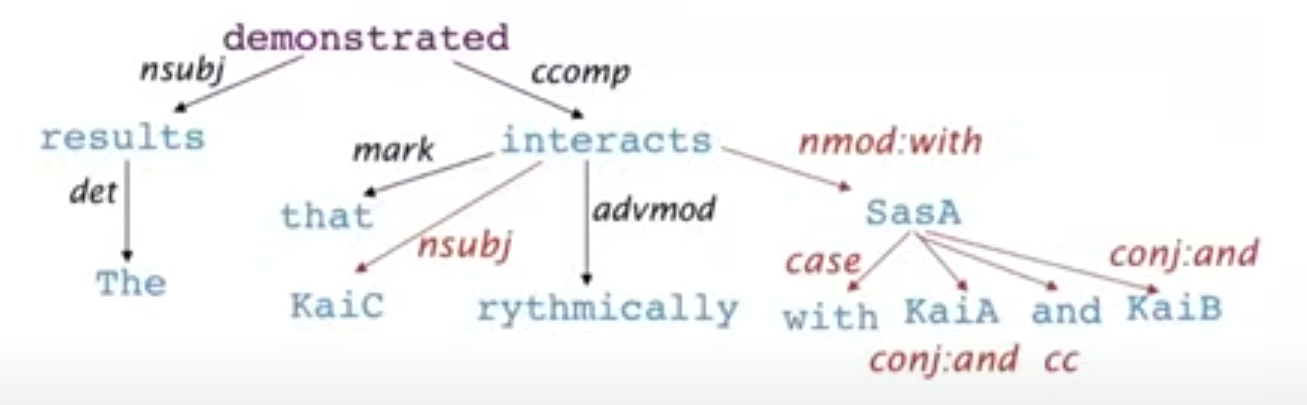
Dependency Structure
通过一个单向边指明依赖关系(同时这个边也会指明依赖关系的种类),进而组成一个树状结构,通常会添加一个虚拟的"ROOT"节点作为根节点

Greedy transition-based parsing

初始状态:\(\sigma=[ROOT],\beta=w_1,...,w_n,A=\empty\)
三种操作:
- Shift : 从缓存区\(\beta\)里面移入一个词到栈\(\sigma\)里面
- Left-Arc : 将\((w_j,r,w_i)\)加入边集合\(A\) ,其中\(w_i\)是stack上的次顶层的词,\(w_j\)是stack上的最顶层的词,然后保留\(w_j\)在栈中(堆必须包含两个单词以及 \(w_i\)不是 ROOT )
- Right-Arc : 将\((w_i,r,w_j)\)加入边集合\(A\) ,其中\(w_i\)是stack上的次顶层的词,\(w_j\)是stack上的最顶层的词,然后保留\(w_i\)在栈中(堆必须包含两个单词以及 \(w_i\)不是 ROOT )
重复上述操作到指定目标.
实际应用的时候,如何判断选择哪一种操作可以通过机器学习的方式来判断,也可以加入集束搜索来寻找最优解.
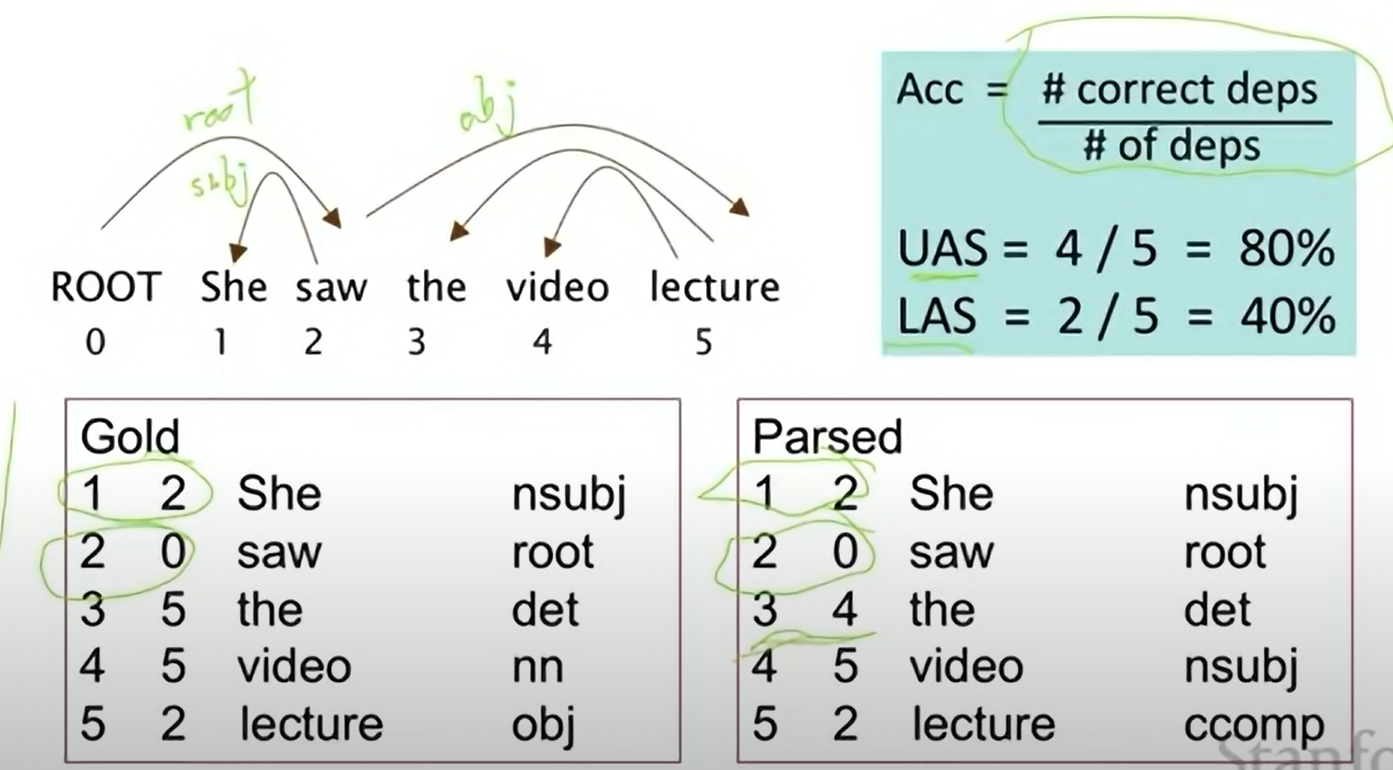
评判标准:
- UAS:找准依赖项的词的比例
- LAS:在UAS基础上,还要求边的属性得准确
示例:
参考资料
Since the comment system relies on GitHub's Discussions feature, by default, commentators will receive all notifications. You can click "unsubscribe" in the email to stop receiving them, and you can also manage your notifications by clicking on the following repositories: bg51717/Hexo-Blogs-comments