todo:本文还在施工中.......
介绍
llm.int8是第一批针对大模型进行量化的算法,并且其算法也被集成在
bitsandbytes库中,该库也已经被
huggingface集成到代码库当中作为最基本的量化算法之一。
论文地址为:[2208.07339] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
摘要
LLM.in8()量化针对的是transformer的FNN模块和Attn模块的矩阵乘法。
该量化方法把矩阵中的异常值抽出来保持16位精度,对于其余值量化为8位精度,计算的时候恢复16精度。量化常数的选择是在向量维度进行的(矩阵最后维度)。
介绍
FFN和Attn的矩阵参数在模型总参数占比较高,且矩阵乘法占据了较多的计算资源。以往的量化方法降低了模型的表现并且需要量化后训练。同时没有对超过350M参数进行量化研究。这篇论文第一次提出针对百万级参数量的模型的量化方法且模型性能下降有限。应该也是第一篇把大模型量化到8比特的论文。
量化前置知识
论文这里简单说明了非对称量化理论上能提供更高的精度,但是由于实际限制,用的最多的还是对称量化。
对称量化
对于fp16格式的输入\(\mathbf{X}_{f16} \in \mathbb{R}^{s \times h}\),8比特的量化为:
\[ \mathbf{X}_{i8} = \left\lfloor \frac{127 \cdot \mathbf{X}_{f16}}{\max_{ij} \left( |\mathbf{X}_{f16_{ij}}| \right)} \right\rceil = \left\lfloor \frac{127}{\|\mathbf{X}_{f16}\|_{\infty}} \mathbf{X}_{f16} \right\rceil = \left\lfloor s_{x_{f16}} \mathbf{X}_{f16} \right\rceil \]
其中\(\left\lfloor \right\rceil\),代表四舍五入取整,即距离最近的整数。
原理介绍
这个量化的方法原理很简单,该方案先做了一个矩阵分解,对绝大部分权重和激活用8bit量化(vector-wise)。对离群特征的几个维度保留16bit,对其做高精度的矩阵乘法。
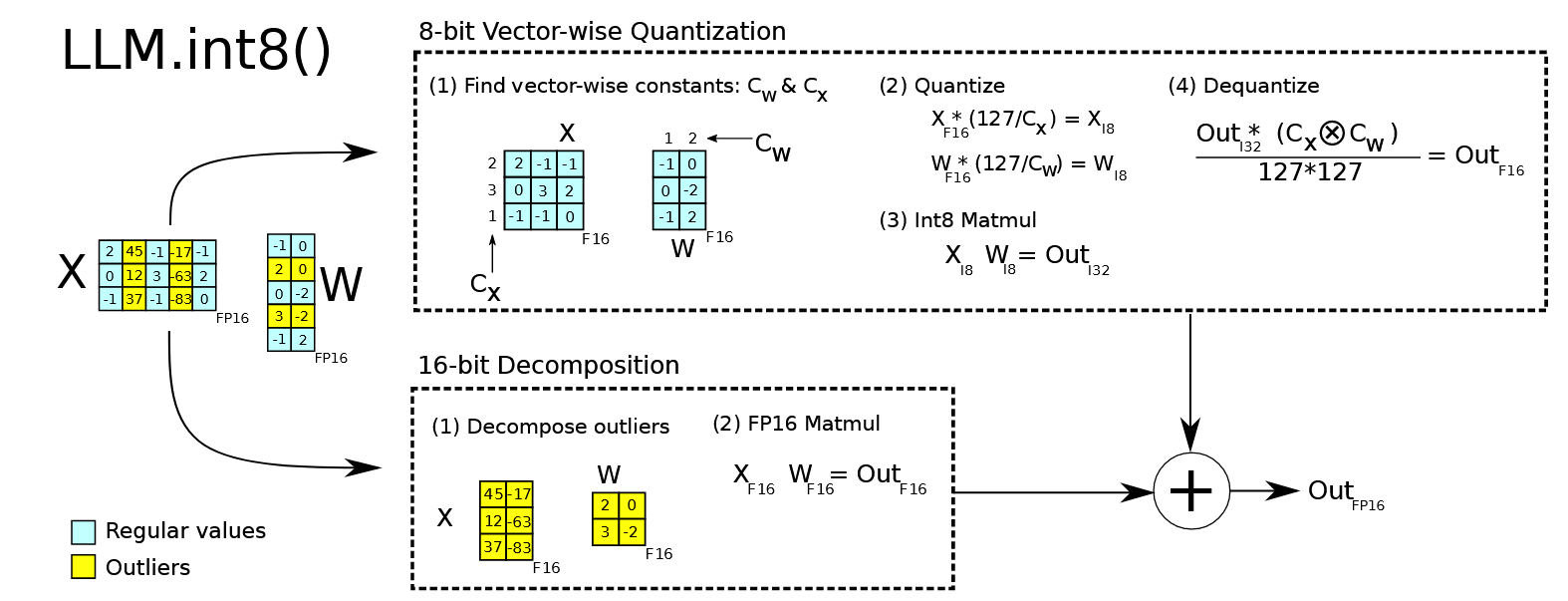
LLM.int8() 通过三个步骤完成矩阵乘法计算:
- 从输入的隐含状态中,按列提取异常维度 (离群特征,即大于某个阈值的值)。
- 对离群特征进行 FP16 矩阵运算,对非离群特征进行量化,做 INT8 矩阵运算;
- 反量化非离群值的矩阵乘结果,并与离群值矩阵乘结果相加,获得最终的 FP16 结果。
原理分析
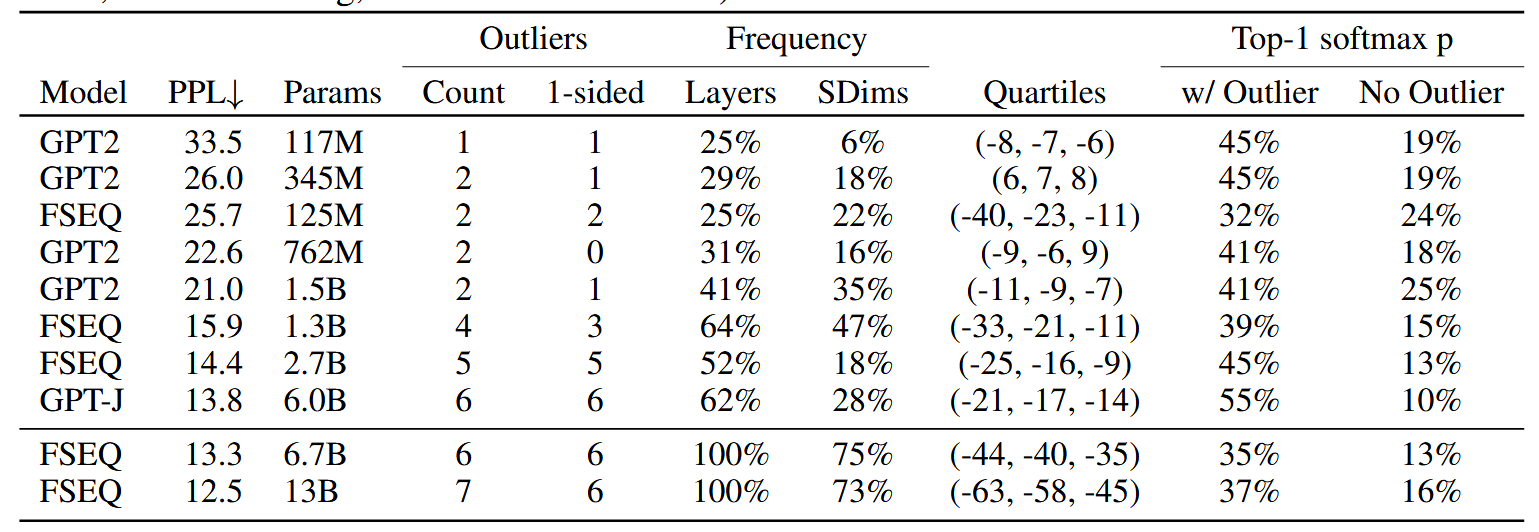
这个方法能成功的一个重要原因是作者发现同一个序列的不同token异常维度集中在部分维度且异常维度数目较少。
首先,论文定义异常值的标准为:
- 值需要大于等于6
- 影响25%的层
- 至少出现一个序列在6%的token中
作者对此进行了解释:
- 实验发现把大于等于6的值设置为异常值,困惑度退化就会停止
- 异常值特征是在大模型中系统出现的,要么出现在大多数层中,要么不出现;在小模型中概率出现。设置该阈值保证125M的最小模型中异常值只有一个(小模型中第二个出现最多的异常值仅仅出现2%的层)
- 使用和第二点相同的过程来选择异常值在序列维度的最小出现比例
作者进行了实验,将满足条件的维度设置为0,比较最高可能性输出类别所分配的Softmax概率值。对比是随机选择相同数目的维度进行对比。
实验
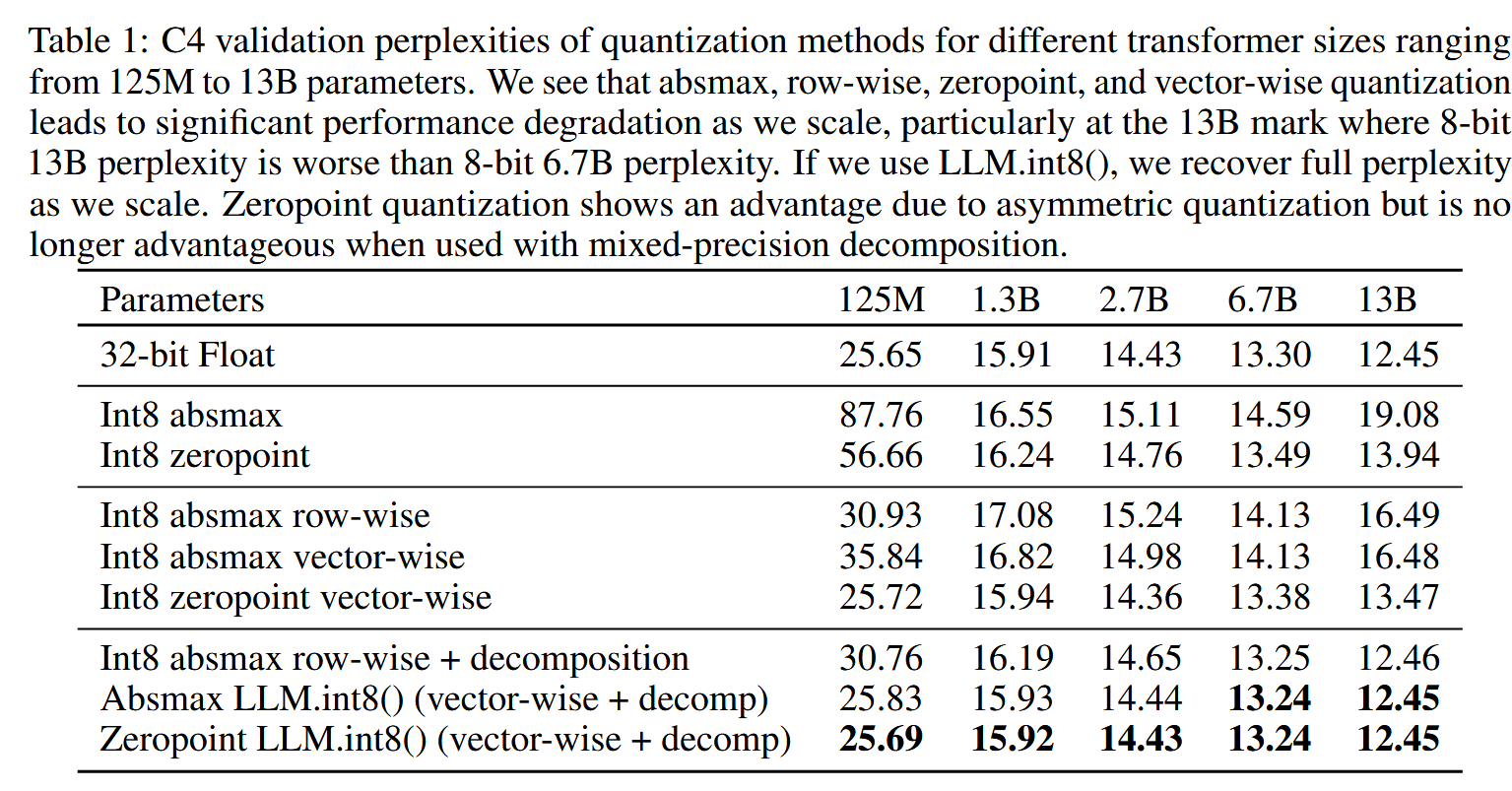
todo:量化效果
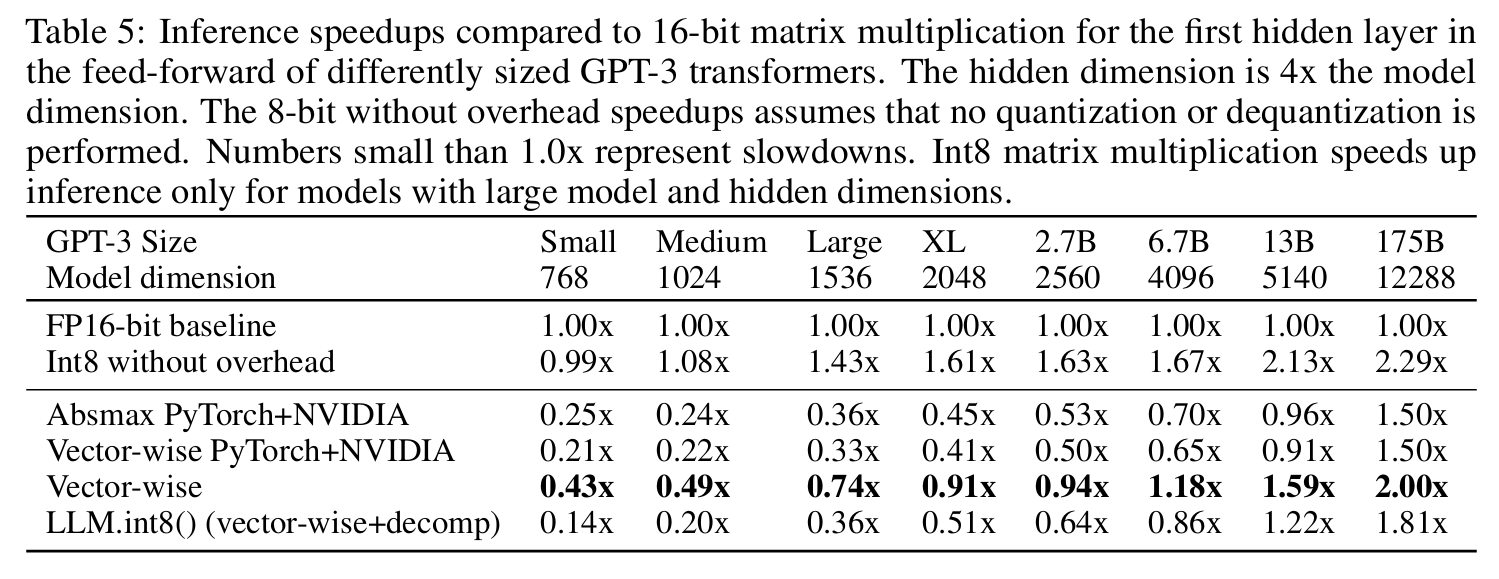
todo:加速效果
由于多余的反量化操作,在小模型上推理速度有所下降。
bitsandbytes介绍
todo:介绍库的大致使用方法和部分疑点。
bitsandbytes库在量化模型的时候,不需要数据首先直接把权重量化为8bit。在推理的时候,根据输入确定异常维度。输入的异常维度保持fp16,别的维度量化为int8。而量化后的权重,会把异常维度进行反量化为fp16(可能会有轻微损失),别的保持int8。之后的计算就和原理图保持一致。



